The Revenue Intelligence Imperative
Why the CPQ architectural decision determines what your company can compound

A capital allocation analysis of the AI-driven revenue stack — and why the architectural decisions being made quietly in 2026 will determine which companies compound margin through 2029
Workflow Economics · No. 4 · May 2026
I. The CFO’s actual question
Companies don’t buy systems. They don’t buy features. They don’t buy categories. They buy outcomes — measurable improvements in the metrics that determine whether the business compounds or stalls. Anyone who has sat through a real CFO conversation about technology investment knows that the deck only matters insofar as it answers a single question, often unstated but always present in the room: what is this going to do to my P&L over the next thirty-six months, and how confident should I be in the number?
The CFO leading a business in 2026 is asking that question against a particularly difficult backdrop. Customer acquisition costs have ratcheted higher across most segments. Deal cycles have stretched. Pricing power is under pressure in the categories where AI has commoditized the underlying capability. Net retention has become harder to defend as buyers consolidate vendors. Forecasts are noisier than they were three years ago because the variance in deal velocity has widened. And meanwhile the AI-driven productivity story keeps showing up in board materials — sometimes credibly, sometimes not — promising that the next eighteen months are about to look very different from the last eighteen.
Inside this environment, the question that actually matters is not “should we upgrade our CPQ system.” That question is downstream, technical, and small. The question that matters is: how do we hit our growth and margin targets in a market that’s changing faster than our cost structure can adapt, and which capital investments in AI will compound that outcome rather than dissipate against it? This is a revenue intelligence question. It is the same question that Gong, Clari, the modern revenue operations function, and the entire AI-and-firm-performance literature have been working on from different angles for the last several years.
There is now a defensible answer to that question. The empirical evidence — which I will walk through below — establishes that AI-driven revenue intelligence is producing measurable lift right now in firms that have deployed it competently. Revenue per employee, deal velocity, pricing realization, net retention, forecast accuracy: each of these is moving in the firms that have solved what the literature calls the AI mapping problem. The lift is meaningful enough to show up on income statements. It is also unevenly distributed, in ways that are not random.
The economic asymmetry, made visible:
The catch — the part that vendor narratives elide and that this paper exists to surface — is that AI-driven revenue intelligence at scale has a binding architectural dependency on the CPQ engine that sits underneath it. If that engine is built around procedural rule cascades and human-UI execution, the agents that drive revenue intelligence have a ceiling on what they can do reliably. If that engine is built around declarative constraint solvers and agent-callable APIs, the ceiling rises substantially. The architectural decision being made quietly in CFO offices today, dressed up as a routine CPQ refresh, is in fact the binding constraint on whether the revenue intelligence outcome the company is investing in actually materializes at the magnitude the business case predicts.
This paper is an attempt to make that dependency legible — and to make the architectural decision a CFO can defend at a board meeting rather than delegate to the CIO. The argument runs as follows. AI-driven revenue intelligence produces measurable lift, supported by peer-reviewed economic evidence. The lift compounds at the firm level when the architecture supports it, not just at the task level. The architectural binding constraint is the CPQ engine — specifically, whether it has crossed the threshold from procedural rule cascades to declarative constraint solvers and agent-callable APIs. Five major CPQ lineages exist, and only two have crossed that threshold; the rest will or won’t, on different timelines, with different commercial consequences. The migration economics for crossing the threshold are favorable when the work is sequenced as a revenue intelligence transformation rather than as a system replacement. And the companies that recognize this in 2026 will compound two to three points of EBITDA margin advantage by 2029, on top of whatever else they are doing.
That last claim deserves the rest of the paper to defend.
II. What revenue intelligence actually is
The category called revenue intelligence is younger than CPQ but older than the agentic enterprise. Gong, Clari, Salesloft, and the broader category established the basic shape of it in the late 2010s: structured data plus AI applied to the revenue function, producing decision support for sellers, deal desk, sales operations, and finance. The early generation focused on conversation intelligence (recording and analyzing sales calls) and pipeline analytics (predicting which deals would close). The category has since broadened.
What revenue intelligence actually is, in 2026, is an architectural pattern more than a product category. It is the application of AI agents and structured data across the entire revenue lifecycle, producing measurable lift in the metrics that determine revenue outcomes. The components, with their corresponding revenue lever:
Pipeline intelligence — agents reading CRM activity, email, calendar, and call data to score deals, predict close probability, and surface risk. Revenue lever: forecast accuracy and pipeline conversion.
Pricing intelligence — agents and analytics surfacing pricing realization, margin leakage, discount drift, and competitive pricing patterns. Revenue lever: average selling price and gross margin.
Deal intelligence — agents analyzing win/loss patterns, deal trajectory, and competitive dynamics to recommend next-best-action and surface coaching opportunities. Revenue lever: win rate and average deal size.
Renewal and expansion intelligence — agents predicting churn risk, identifying expansion timing, and surfacing health signals from product usage and customer interactions. Revenue lever: net revenue retention.
Revenue forecasting — multivariate, agent-augmented forecasting that improves on the human-aggregation baseline. Revenue lever: forecast accuracy and capital allocation efficiency.
Contract intelligence — agents reading and analyzing contracts at scale to surface obligations, renewal terms, pricing commitments, and risk. Revenue lever: revenue recognition compliance and renewal capture.
Quote-to-cash velocity — agents driving the quote, configuration, approval, contract, and order processes to compress cycle time. Revenue lever: cash conversion cycle.
The unifying thread across these components is that they all depend on agents reasoning over structured revenue data and acting on it. The agent layer is the differentiator from the previous generation of revenue tools, which were dashboards. The structured data is the dependency. And the system that produces the structured data — the system of record for what gets sold, how it’s configured, what it costs, and what concessions can be made — is the CPQ engine.
This is the analytical reframe that matters. CPQ is not a peer of revenue intelligence in the buying decision. It is a layer underneath revenue intelligence, the substrate that determines whether the intelligence layer can actually function at scale. Buying revenue intelligence without addressing the CPQ architecture underneath is buying the dashboard without the data plumbing. It will produce some value — analyst studies suggest 10–20% lift on individual metrics — but it will not compound the way it does in firms where the architecture is correct end to end.
III. The empirical evidence — what AI-driven revenue intelligence actually produces
The peer-reviewed literature on AI’s effect on firm performance has matured substantially in the last twenty-four months, and the evidence base for the revenue intelligence outcome is now stronger than it has been at any point in the AI cycle. Three studies in particular establish the empirical foundation.
The most directly relevant is Kim, Kim, and Koning (2026), an INSEAD and Harvard Business School working paper that ran a controlled field experiment across 515 high-growth firms. Treated firms received structured information about how peer firms had reorganized production around AI, prompting them to search for use cases across a broader set of functions. The control group did not. The findings, in plain language: treated firms discovered 44% more AI use cases. They completed 12% more tasks. They were 18% more likely to acquire paying customers. They generated 1.9× more revenue. The authors frame the central insight as the mapping problem — the bottleneck on AI value creation is not access to the technology, not skill in using it, not even willingness to adopt. It is the cognitive search problem of identifying where in the firm’s production process AI actually creates value.
This is the most economically significant AI-and-firm-performance study published to date, and it directly grounds the revenue intelligence claim. AI applied to the right parts of the production process produces capital efficiency at the firm level, not just task-level productivity gains.
The second foundational reference is Brynjolfsson, Li, and Raymond, originally NBER Working Paper 31161 in 2023 and now published in The Quarterly Journal of Economics, which documented 14% average productivity gains from generative AI deployment in a customer service context, with substantially larger gains for less-experienced workers. This is the evidence that AI productivity effects are real at the task level — a necessary condition for the firm-level mapping argument to translate into revenue outcomes. Dell’Acqua et al. (2023, forthcoming in Organization Science), the Harvard “Navigating the Jagged Technological Frontier” paper, provides the crucial heterogeneity finding: AI gains are not uniform. Tasks that fall inside the frontier of AI capability get faster and better; tasks that fall outside it get worse when AI is applied. This matters for the architectural argument because the difference between agent-callable CPQ APIs and procedural-rules CPQ APIs is precisely the difference between an inside-the-frontier task (deterministic, idempotent, structured) and an outside-the-frontier task (non-deterministic, stateful, ambiguous).
The fourth pillar of the evidence base is consultancy-grade survey data. McKinsey’s Global Tech Agenda 2026 — based on a survey of 632 C-level executives and IT leaders conducted in late 2025 — establishes that the architectural divide is showing up in 2026 spending plans as a leading indicator. Top-performing companies (those with 10%+ revenue and EBIT growth over three years) are planning tech budget increases of more than 10% at nearly an order of magnitude higher rate than other organizations: 28% versus 3%. They are nearly twice as likely to have CIOs deeply involved in shaping enterprise strategy (64% versus 52%, rising to 74% at organizations with $500M+ tech spend). They have adopted product-and-platform operating models at four times the rate of other organizations. McKinsey’s framing of the underlying shift — that “technology’s center of gravity has shifted from a cost center to a value creator” and that “infrastructure modernization is no longer a strategy; it’s a stall” — is directly aligned with the revenue intelligence imperative this paper articulates. McKinsey also surfaces the architectural constraints honestly: among organizations attempting to scale agentic AI, 31% cite talent and capability gaps as the top challenge, 29% cite integration complexity with existing systems, and 21% cite lack of modern data foundations. These are the operational symptoms of the architectural ceiling that this paper identifies as the binding constraint on revenue intelligence outcomes. A reader skeptical of the academic working-paper evidence will find the McKinsey survey data directly corroborating, and a reader skeptical of survey data will find the academic studies directly corroborating; the convergence between the two evidence streams is unusually strong for a topic this new.
It is worth pre-empting one apparent tension in the evidence. McKinsey’s data shows that intent to pursue AI-driven IT transformation is relatively similar across top performers and others — 45% versus 40% — which a skeptical reader could cite as evidence that the architectural divide is narrower than this paper claims. The honest reconciliation is that intent gaps are narrower than capability gaps. The same McKinsey data shows top performers are 26 percentage points more likely to have CIOs deeply involved in strategy, 25 percentage points more likely to plan budget increases above 10%, and 4× more likely to have fully adopted modern operating models. The architectural divide is structural; intent alone does not capture it, because intent without the architectural foundation produces the analytical-only revenue intelligence ceiling rather than the compounding outcome.
The pattern across the literature is consistent. AI-driven revenue work produces measurable lift when deployed against the right problems with the right architectural foundations. The lift compounds at the firm level when capital efficiency and revenue velocity move together. And the firms that capture the lift are not distinguished from the firms that don’t by their access to AI; they are distinguished by whether they have solved the mapping problem and built the architectural foundation to support it.
For revenue work specifically, the mapping problem has been substantially solved by the industry over the last two years. The high-value applications are now well understood: pipeline intelligence, pricing realization, deal velocity, renewal prediction, forecast accuracy, contract analysis, quote-to-cash compression. The bottleneck on capturing the gains has shifted from “where do we apply AI” to “can our architecture support AI agents operating reliably across the revenue function.” This is where the CPQ architectural decision becomes binding.
IV. The gating dependency
The architectural argument is straightforward, even if its implications are not.
AI agents driving revenue work — pricing analysis, deal scoring, configuration, quote generation, contract review, renewal forecasting, revenue recognition — need to read structured data from the system of record and, in the more advanced applications, write back to it. They need to do this reliably, at scale, with predictable cost economics, and with sufficient determinism that downstream systems can trust the outputs. They need to do it with enough latency budget that multi-turn reasoning loops do not blow up wall-clock time and inference cost. And they need to do it with enough error transparency that failures can be diagnosed, attributed, and corrected.
Every one of these requirements maps to a property of the underlying CPQ engine.
If the CPQ engine produces inconsistent intermediate states between rule fires (which procedural rule cascades do by design), agents reading from it will sometimes see invalid configurations, sometimes see incomplete pricing, and sometimes commit decisions to downstream systems that have to be rolled back. If the CPQ engine has stateful, session-bound APIs, agents lose work when context windows roll over and have to restart sessions from scratch, multiplying cost and degrading reliability. If the CPQ engine returns errors as stack traces or generic failure codes rather than structured semantics, agents cannot recover from failures and have to escalate to humans, which collapses the productivity argument. If the CPQ engine has 2-to-4 second latency on pricing recalculation (which Apex-governor-bound systems and AJAX-coupled UIs typically do), every agent loop that touches pricing pays that latency multiple times, and reasoning model token costs scale accordingly. If the CPQ engine surfaces tool descriptions that consume thousands of tokens per request, the practical agent surface area is bounded before the agent can do meaningful work.
These are not theoretical concerns. They are observable failure modes in production agentic deployments today. They are also concentrated specifically in CPQ engines built around procedural rule cascades and human-UI execution, which describes most of the installed base.
The bound is not soft. Revenue intelligence at the magnitudes the literature documents — 1.9× revenue lift, double-digit gains across task-level productivity, capital efficiency improvements that show up at the firm level — depends on agents being able to operate reliably across the revenue function. The CPQ engine is the largest single tool in that function by transaction volume and economic consequence. If it cannot support reliable agent operation, the revenue intelligence outcome is bounded by the fraction of work that can be done outside the CPQ — which is the analytical and conversational layer (pipeline intelligence, deal intelligence, conversation intelligence) but not the transactional layer (pricing, configuration, quoting, contracting). That analytical-only ceiling captures roughly 30–50% of the value the integrated stack can deliver. The other 50–70% requires the architectural change.
This is the gating dependency. The CPQ engine is not the prize. It is the door.
The architectural pattern, made visible:
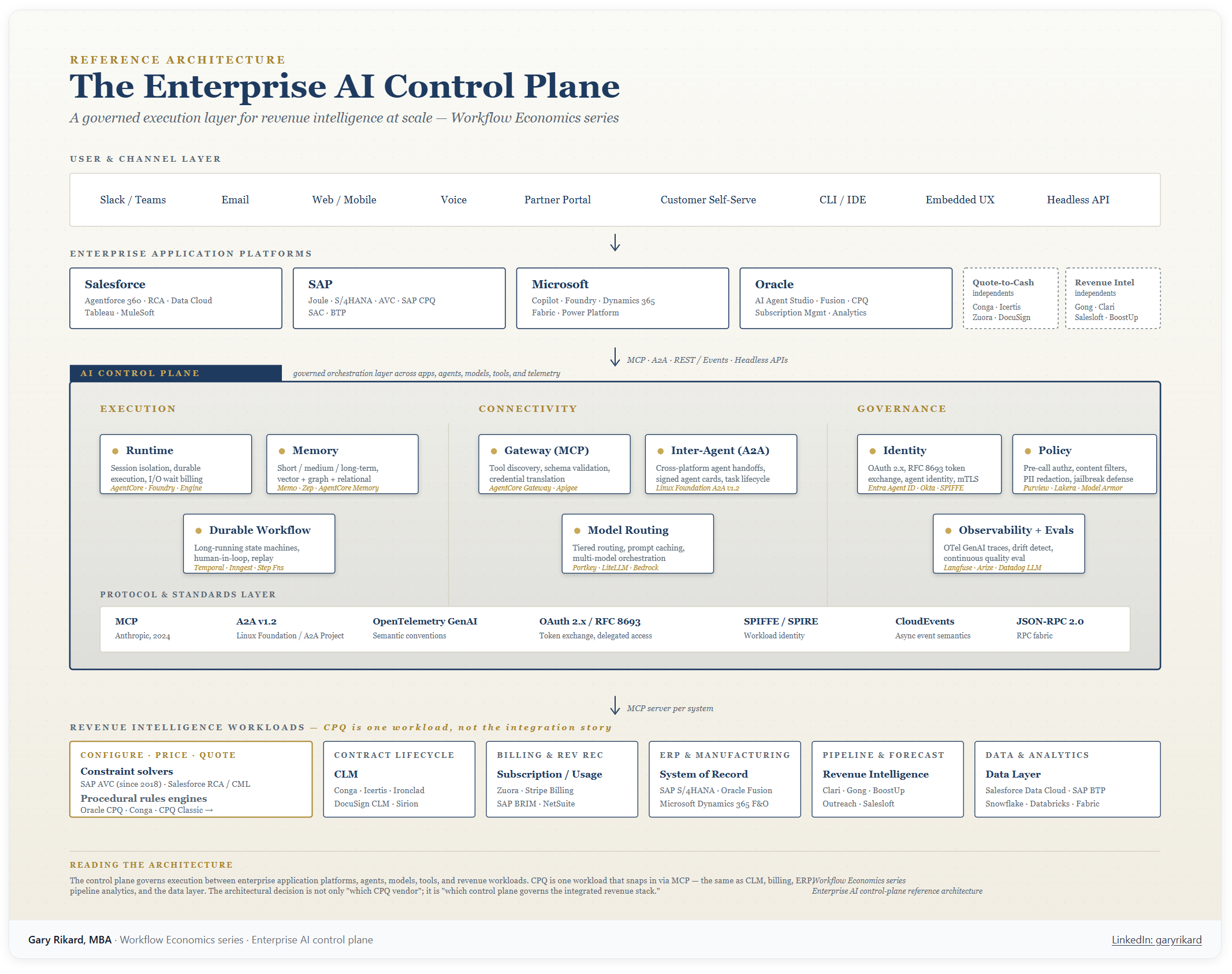
V. The CPQ architecture, in service of the revenue intelligence outcome
What follows is the technical analysis of the five CPQ lineages — Oracle CPQ (descended from BigMachines), Salesforce CPQ Classic (descended from Steelbrick), Conga (descended from Apttus), SAP’s Variant Configuration and SAP CPQ stack, and Salesforce Revenue Cloud Advanced (descended from Vlocity) — viewed through the lens of which ones support agent-driven revenue intelligence at scale and which ones bound it. The level of technical depth is necessary because the architectural decision is the binding constraint; it is not an end in itself.
Configuration, in computer science terms, is a constraint satisfaction problem. Given a finite product domain and a set of constraints between options, find a valid assignment of selections. Pricing is a directed acyclic graph of conditional computations. Quoting is document assembly with workflow. The early CPQ engines treated configuration as a procedural rule cascade — if A then B — and fired the rules sequentially. This is computationally adequate for simple bundles and inadequate for genuinely complex catalogs, because rule cascades cannot reason about global feasibility. Modern engines are converging on actual constraint solvers — declare the constraints, let the solver find feasible and optimal configurations — which is what computer science has known is the right approach since the 1980s but only became economically practical in the cloud era for the SaaS front-office segment, and was first deployed at production scale in the industrial manufacturing segment in the late 2010s.
The five lineages have made different architectural choices and have crossed (or failed to cross) the constraint-solver threshold at different points.
Oracle CPQ, descended from BigMachines (founded 2000), shipped a proprietary scripting language called BML, a two-document architecture separating Configuration from Commerce, and BOM-native semantics that genuinely model industrial product hierarchies. It has been kept current with Redwood UX, Asset-Based Ordering, subscription pricing, and AI features through Oracle’s broader Fusion stack. But the core paradigm is the same forward-chaining rules engine BigMachines shipped in the early 2000s. There is no constraint solver. AJAX-driven rule firing is intrinsically UI-coupled. For revenue intelligence purposes, this means agents calling Oracle CPQ get the result of whatever sequence of rule fires happened to occur, which is correct often enough to be misleading and inconsistent often enough to be unreliable.
Salesforce CPQ Classic, descended from Steelbrick (acquired 2015), is a managed package on the Salesforce platform with rule cascades running in Apex inside multi-tenant governor limits. Configuration logic lived in records that fired in a defined sequence; custom logic was injected through JavaScript hooks (QCP). This is not a constraint solver and never was. Quotes north of about 200 line items become operationally painful. The product is now on the path to maintenance mode. New investment here in 2026 is a strategic mistake.
Conga CPQ, descended from Apttus (merged with Conga in 2020), executed a microservices rewrite onto AWS, exposing 500+ APIs and decoupling compute from Salesforce governor limits. The configuration engine remains rule-based rather than constraint-solving — a real architectural ceiling — but the platform topology is genuinely modern and the API surface is mature enough to support agent-callable patterns. For organizations that want CPQ + CLM + revenue lifecycle as an integrated platform that is not coupled to the Salesforce platform’s rate of change, Conga is the most credible offering. The constraint-solver gap matters less for catalogs of moderate complexity and more for industrial-scale configurations.
SAP is the lineage most enterprise readers underweight. SAP has shipped variant configuration since R/3 in the early 1990s as LO-VC (Logistics Variant Configuration), the longest production history in the category. In 2018, SAP shipped Advanced Variant Configuration (AVC) on S/4HANA, which is a true declarative constraint solver built on the Gecode constraint-programming library. AVC crossed the paradigm threshold first in the industrial manufacturing market — six years before Salesforce did the same on the SaaS front-office side. SAP CPQ, originally acquired from CallidusCloud, sits on the front-office side of the stack and integrates with AVC to produce a unified configuration model that spans sales-side quoting and manufacturing-side production. This unified model is genuinely unique among the five lineages. For organizations whose products are configured in manufacturing and sold through enterprise sales motions — capital equipment, industrial machinery, automotive, aerospace, medical devices, telecommunications infrastructure — SAP’s combined AVC + SAP CPQ stack on S/4HANA with Joule as the agentic layer is the most architecturally coherent option in the market.
Salesforce Revenue Cloud Advanced, descended from Vlocity (acquired 2020), is the rebuilt platform that crosses the constraint-solver threshold for the SaaS-and-services segment. It uses a declarative configuration model language called CML, runs on Hyperforce, and includes built-in optimization goals (revenue maximization, margin maximization, customer LTV) that procedural-rules engines cannot express. With the April 2026 announcement of Headless 360, Salesforce committed to making the entire platform — including RCA, Agentforce, Data Cloud, and the broader Customer 360 — accessible without a UI, executable through agents, with the same governance and access controls that apply to human users. This is the architectural completion of the constraint-solver-plus-agent-layer pattern that AVC established in the industrial market and that RCA now establishes in the SaaS-and-services market.
Two of the five lineages have crossed the constraint-solver threshold (SAP AVC since 2018, Salesforce RCA since 2024). Two have not and have no announced architectural roadmap to suggest they will (Oracle CPQ, Conga CPQ — both have made meaningful investments in other dimensions, but neither has shipped a constraint solver). One is in maintenance mode and will not cross (Salesforce CPQ Classic).
For a revenue intelligence buyer, this is the architectural map. The two engines that have crossed support agent-driven revenue work at the magnitudes the empirical literature suggests are achievable. The other three bound it.
VI. The agentic inflection — and what it costs
The technical case for crossing the constraint-solver threshold has become economically urgent in 2026 because of two developments that are independent of CPQ but that interact with the CPQ architecture in consequential ways.
The first is the arrival of frontier reasoning models — Claude Opus 4.7, GPT-5.5, Gemini 3 Pro — and the standardization of agent tool-use through the Model Context Protocol, which Anthropic originated in late 2024 and which is now an open standard with industry-wide adoption. The protocol race is over; every major application platform speaks MCP. The second is the emergence of the AI control plane as a distinct platform category — AWS AgentCore, Microsoft Foundry, Salesforce Agentforce, SAP Joule, Google’s Gemini Enterprise, Oracle’s AI Agent Studio — that handles the runtime, identity, gateway, memory, observability, and policy primitives that any production agentic system requires. McKinsey’s Global Tech Agenda 2026 names this layer in equivalent terms, describing the intelligence layer as “a unified set of data, AI models, and decision systems that serve as the control plane of the enterprise” — a vocabulary convergence that signals the category has crossed into mainstream strategic discourse. The Linux Foundation’s Agentic AI Foundation now governs the Agent-to-Agent protocol that handles agent communication across platform boundaries.
A structurally significant pattern within this layer, easy to miss but consequential for the buying decision: the application platforms are converging on multi-model orchestration rather than single-model bundling. The Salesforce-Google integration of Gemini Enterprise into Agentforce is the most prominent recent example. The implication for revenue intelligence economics is that the model choice is no longer bundled with the application platform choice. Customers picking Agentforce now have access to Claude (default for conversational and tool-use reasoning), Gemini (advantaged on long-context document work and multimodal handling), and others through the same orchestration layer. SAP’s Joule is on a parallel trajectory. The practical effect is that customers should evaluate the application platforms on orchestration depth and control plane primitives, then separately set the model routing strategy that fits the workload mix — which produces measurably better unit economics than treating these as a bundled decision, because reasoning workloads have heterogeneous characteristics (token volume, context length, multimodal requirements, latency sensitivity) that benefit from differentiated model routing.
For revenue intelligence purposes, what matters is the economics. Reasoning models produce internal reasoning traces that occupy context window space and are billed as output tokens. A complex configuration session can burn 200,000 to 500,000 tokens including reasoning. At Claude Opus output pricing of roughly $25 per million tokens, a single quote can cost several dollars in inference alone. Tool descriptions inflate every request. Multi-turn loops compound. A single user-facing CPQ task typically decomposes into 8 to 15 tool calls, each carrying accumulated history.
The interaction between agent economics and CPQ architecture is direct. A reasoning-model agent calling a procedural-rules CPQ with 2-to-4 second pricing recalculation latency burns wall-clock time in retries and context bloat. Per-quote inference cost can run several dollars in tokens with 30 to 60 seconds of latency, which is economically and experientially unacceptable at scale. A well-architected agent flow against a sub-second deterministic constraint-solver CPQ runs a fraction of that, with predictable behavior. Three years of compounding per-quote efficiency advantage produces structurally different revenue cost ratios.
The control plane question matters because the CPQ engine sits inside it as one workload among many. Whether the agentic revenue architecture sits on Salesforce Agentforce, SAP Joule, AWS AgentCore, Microsoft Foundry, or some federation across them is a strategic decision that interacts with the CPQ architectural decision in non-trivial ways. SAP-anchored customers running AVC + SAP CPQ + Joule have all the components in a single tenant, with one identity model, one policy framework, one observability stack. Salesforce-anchored customers running RCA + Agentforce 360 have the same property within the Salesforce fabric. Customers running mixed stacks — Oracle ERP plus Salesforce CRM plus SAP manufacturing plus a third-party CPQ — have a multi-platform orchestration problem that the A2A protocol partially addresses but does not fully solve. The honest framing for these customers is that the CPQ migration economics double as a control plane consolidation question.
For revenue intelligence economics, this is the practical implication: the EBITDA case is bounded by the worst-orchestrated component in the revenue stack, not by the best. A best-in-class RCA deployment that has to integrate across a poorly-orchestrated SAP backend produces less compounding revenue intelligence value than a coherent SAP-native AVC + SAP CPQ + Joule stack, even though the standalone CPQ engine in the first case is more architecturally modern. The reverse is also true: a well-orchestrated mixed-vendor stack with explicit A2A handoffs and unified identity can outperform a coherent single-vendor stack that has been deployed without architectural rigor. The architecture matters more than the vendor selection.
VII. The buying framework, revenue intelligence edition
The buying framework for revenue intelligence transformation is fundamentally different from the framework for CPQ replacement. The buying decision is not “which CPQ vendor” but “which integrated revenue intelligence architecture compounds outcomes the fastest given my starting point.” The components of the integrated stack vary by vendor:
Salesforce: Revenue Cloud Advanced + Data Cloud + Agentforce 360 + Tableau + MuleSoft. Strongest for SaaS-native organizations with Salesforce as the existing center of gravity for CRM and sales execution. The Agentforce Revenue Management rebrand reflects that Salesforce sees revenue intelligence as the strategic frame. The architectural foundation is now correct. Integration depth across the components is the highest in the industry within the Salesforce ecosystem.
SAP: AVC + SAP CPQ + SAP Sales Cloud + SAP Analytics Cloud + Joule, on S/4HANA and BTP. Strongest for industrial manufacturing organizations anchored on S/4HANA. The unified configuration model spanning sales and manufacturing is unique to SAP among the five lineages. Joule’s in-tenant operation across the full revenue stack produces a structurally cleaner agentic topology than cross-vendor integration. The CPQ component on its own is unremarkable; the architectural value is in the integrated stack.
Microsoft: Dynamics 365 + Microsoft Fabric + Copilot + Power Platform. Strongest for organizations whose center of gravity is Microsoft (Office, Teams, Azure). The CPQ capability in Dynamics has been less differentiated historically, but the surrounding stack — particularly Fabric for the data layer and Copilot for the agentic layer — is competitive. For mixed Microsoft-and-other-platform environments, Microsoft is increasingly a credible center of gravity for the control plane even when the transactional CPQ runs elsewhere.
Oracle: Fusion Cloud Sales + Oracle CPQ + Oracle Subscription Management + Oracle AI Agent Studio + Fusion Analytics. Strongest for organizations already deeply invested in Oracle Fusion or E-Business Suite at the ERP layer. The architectural ceiling on the CPQ engine is real; the broader Oracle stack compensates partially through the unified data and agent layers, but the procedural-rules CPQ remains a binding constraint on agentic revenue intelligence.
Independents at the intelligence layer: Gong, Clari, Salesloft, Outreach, BoostUp, and the broader revenue intelligence category. These do not own the transactional layer; they consume data from it. They are credible as the intelligence layer in any of the four center-of-gravity scenarios above, particularly for organizations that want best-in-class conversation intelligence and pipeline analytics regardless of their underlying CPQ. The honest assessment is that these tools provide meaningful lift on the analytical side of revenue intelligence — pipeline scoring, deal forecasting, conversation analysis — but cannot solve the transactional-layer architectural ceiling on their own.
Independents at the quote-to-cash transactional layer: Conga, Icertis, Zuora, DocuSign CLM. These are credible alternatives or complements to the major application platforms for specific revenue-stack components. Conga in particular sits in a strong position because it offers an integrated CPQ + CLM + revenue lifecycle platform on a modern microservices architecture that is not coupled to the Salesforce platform’s rate of change. For organizations that want platform-neutrality at the transactional layer — particularly those with mixed-vendor stacks at the CRM and ERP layers — Conga is the strongest play. Icertis leads on CLM-first deployments; Zuora on subscription billing; DocuSign CLM for organizations with existing DocuSign signature footprints.
Integration substrate: MuleSoft (Salesforce-owned but architecturally independent), Boomi, Workato, n8n, Apigee. These are not application platforms; they are the iPaaS and orchestration layer that connects systems of record across vendor boundaries. For organizations running mixed-vendor revenue stacks, this layer is where the cross-platform agentic workflows actually execute — and where the choice of integration tooling materially affects whether MCP servers and A2A handoffs perform reliably in production. The integration substrate is partially absorbed by the AI control plane in single-vendor scenarios (Salesforce-anchored stacks lean on MuleSoft + Agentforce, SAP-anchored stacks lean on BTP Integration Suite + Joule), but remains a distinct architectural layer for any organization with material heterogeneity in its application platform footprint.
A note that applies across all five center-of-gravity scenarios: model selection is now decoupled from application platform selection. The Salesforce-Google integration of Gemini Enterprise into Agentforce, parallel moves at SAP and Microsoft, and AWS AgentCore’s framework-and-model-agnostic posture all establish that picking an application platform no longer locks the customer to a specific reasoning model. For revenue intelligence workloads — which have heterogeneous characteristics across pipeline analysis, document review, conversation intelligence, and transactional configuration — this is economically meaningful, because tiered model routing typically produces 40–60% inference cost reduction without quality loss. The buying decision should be: pick the application platform on orchestration depth and control plane primitives, then set the model routing strategy as a separate decision optimized to the workload mix.
The architectural diagnostic question that cuts through everything else, reframed as a revenue intelligence question: can an agent reliably read from and write to this revenue stack across the full quote-to-cash lifecycle without a human babysitting? The answer depends as much on the integration architecture as on any individual component. Two of the five CPQ lineages can answer yes today on the engine layer (SAP AVC and Salesforce RCA, in different parts of the market). Whether the answer is yes at the stack level depends on the rest of the architecture.
The integration architecture point deserves emphasis because the empirical evidence is now strong enough to be cited. McKinsey’s Global Tech Agenda 2026 surfaces, from a survey of 632 C-level executives, that the three top-cited challenges in scaling agentic AI are talent and capability gaps (31% of respondents), integration complexity with existing systems (29%), and concerns about security, reliability, and hallucinations (26%). Lack of modern data foundations (21%) compounds these. The pattern across the survey data is unambiguous: organizations attempting agentic AI deployment are hitting integration and capability constraints, not technology constraints. The reasoning models work; the application platforms speak MCP; the agentic frameworks ship in production. What fails is the integration competence required to connect them across vendor boundaries, with appropriate identity federation, observability, and continuous evaluation. This is the operational symptom of the architectural ceiling that this paper identifies, and it is also the layer where the choice of implementation partner determines whether deployments compound value or stall in pilot.
VIII. The migration economics — revenue intelligence transformation, not system replacement
The migration economics for crossing the architectural threshold are favorable for most enterprises with material revenue load, but the framing matters more than the math. Companies that frame this as a CPQ replacement project produce one set of business cases and execution risks. Companies that frame it as a revenue intelligence transformation produce a different set, with substantially better economics on both sides of the ledger.
The EBITDA levers from a successful revenue intelligence transformation, in ranges from active programs and consistent with the empirical literature:
Forecast accuracy improvement of 10 to 25 percent, which compounds into capital allocation efficiency at the firm level. Pipeline conversion lift of 5 to 15 percent through agent-augmented deal scoring and next-best-action recommendations. Average selling price improvement of 1 to 4 percent through pricing intelligence, leakage detection, and discount discipline — a revenue lever that scales linearly with revenue base and is therefore disproportionately valuable for larger firms. Net retention improvement of 2 to 5 points through renewal intelligence and expansion timing. Quote-to-cash cycle compression of 20 to 40 percent through agent-driven configuration and approval. Quote desk and revenue operations FTE redirection of 15 to 30 percent.
For a $500 million software-and-services business, the run-rate value compound from a successful revenue intelligence transformation is usually $20 to 50 million annual within 24 to 30 months of stable operation. Against transformation spend in the $5 to 15 million range across the full program (intelligence layer, catalog rationalization, CPQ engine migration, control plane build), payback periods of 6 to 18 months are the working range, conditional on execution.
Specific revenue intelligence subworkflows show different ROIC profiles inside this aggregate — pipeline forecasting in the 50–70× range, churn prediction in the 5–20× range, pricing optimization in the 2–8% margin-expansion range — depending on data readiness, signal threshold, and where the workflow sits relative to the jagged frontier of AI capability. The aggregate EBITDA case for a transformation program is the integral across these subworkflows; the highest-velocity returns come from the analytical-layer workflows that do not depend on the CPQ architectural change, which is why the staged approach below sequences them first.
Run your own numbers. An interactive version of this model — Revenue Intelligence Economic Multiplier — lets readers test the framework against their own revenue base, improvement lever, gross margin, and AI investment level. The economic asymmetry the calculator surfaces — that a 2% improvement lever on a $500M revenue base produces 5× ROIC at $1M of AI investment, with the multiple scaling inversely with investment size — is the structural reason this category of capital allocation does not have a peer in a typical CFO budget. AI investment runs at 0.02–0.1% of the revenue base it improves; no other line item in a CFO’s planning produces this ratio. Available at grikard.github.io/revenue-intelligence-calculator.
The execution risk is concentrated in two places. The first is the catalog rationalization step that has killed every previous generation of CPQ migration; carrying duplicated SKUs, undocumented bundle dependencies, free-text product descriptions, and inconsistent attribute models into the new system produces a stack that is just as hard to operate as the old one. The second is the mapping problem the Kim, Kim, and Koning paper identifies — firms that deploy AI without identifying the right value-creating use cases produce sub-scale gains that don’t compound. Both risks are addressable through staging.
The staged approach that holds up in front of a CFO and an investment committee:
Months 0–6: intelligence layer, no architectural commitment. Stand up a unified data layer (Data Cloud, BTP, Snowflake, Fabric, or equivalent) and wrap the existing CPQ in read-only MCP servers. Deploy the analytical-side revenue intelligence — pipeline scoring, deal intelligence, pricing analytics, forecast augmentation, conversation intelligence. Spend in the $500K to $2M range. Capture the 30–50% of revenue intelligence value that does not require the architectural change. Generate the firm-specific data that proves the rest of the business case in numbers, not vendor assertions.
Months 6–12: catalog rationalization on the target architecture. Build the future-state catalog on whichever platform the architectural analysis selected — RCA, AVC, or another. New SKU structure, attributes, dependencies, pricing logic, all clean. Spend in the $1 to 4M range. The legacy engine continues to run production transactions throughout. The catalog work is the highest-leverage prep work for the architectural change and is independently valuable as data quality improvement even if the engine migration is delayed or canceled.
Months 12–18: configurator and pricing migration by business unit or product line. Constraint models and pricing procedures stand up in production for the first migrated cohort. In-flight quotes finish on the legacy engine; new quotes start on the new one. Spend in the $2 to 6M range. The transactional-layer revenue intelligence levers — pricing realization, quote velocity, configuration accuracy — begin compounding.
Months 18–24: agent-native revenue experience. Headless agent flows on the new platform. Deal desk transformation. Full revenue intelligence loop closing across analytical and transactional layers. Spend in the $1 to 3M range. Full run-rate value materializes.
The total committed spend across the program is comparable to a single failed monolithic CPQ migration attempt, with substantially lower execution risk because each phase is independently value-positive. The legacy engine carries production transactions throughout. The intelligence layer captures partial-stack value in two quarters. The catalog rationalization is decoupled from the engine cutover. The control plane investment runs in parallel and delivers value in its own right.
The dependency that vendor narratives elide and that this paper exists to surface: the revenue intelligence outcome compounds when the architectural foundation is correct end to end. The intelligence layer alone produces 30–50% of the achievable lift. The architectural change produces the other 50–70%. Companies that invest in the intelligence layer without addressing the CPQ architecture underneath will deliver some value, plateau at the analytical-only ceiling, and watch competitors who completed the full architectural transition compound past them through 2028 and 2029.
IX. The strategic close
The companies sitting on Salesforce CPQ Classic, Oracle CPQ, or unmigrated SAP LO-VC today are not at immediate competitive risk. They will not lose the next deal because their CPQ is on a procedural-rules architecture. The risk is slower-burning and more dangerous: they will lose the next three years of operating leverage as competitors who started the staged revenue intelligence transformation in 2024 and 2025 compound their AI-driven quote-to-cash economics. By 2028 and 2029, the gap between an agent-native revenue stack and a procedural-rules CPQ with bolt-on AI is going to look the way the gap between cloud and on-premise looked in 2015 — visibly structural, with a closed window for catch-up.
The architectural decision being made in CFO offices today is a capital allocation decision with three-to-five-year compounding consequences, sitting inside what looks like a routine vendor evaluation. The companies that recognize what is actually being decided will sequence the work to capture intelligence-layer wins in two quarters, prove the business case with their own data, and only then commit to the architectural change.
A useful historical parallel, for the executives who think in those terms: the database industry went through this paradigm shift in the 1980s, when the navigational databases that had served business reasonably well for two decades were displaced by relational databases with a declarative query language. The companies that recognized SQL as a paradigm shift, not a feature, captured a generational productivity advantage. The companies that treated it as a routine technology refresh got lapped, and stayed lapped, for the next twenty years. CPQ is having its SQL moment — quietly, in different segments at different times. SAP’s industrial customers crossed the threshold first, with AVC in 2018. Salesforce’s SaaS-native customers are crossing it now with RCA. Oracle’s customers and Conga’s customers will face the question next, when their procedural-rules architectures fail under agent-driven load.
The CFOs and architects who recognize what is actually being decided will compound. The ones who don’t, won’t.
The ask for executive teams reading this paper is straightforward and sequenced.
First: commission an honest revenue intelligence assessment, anchored on what the firm-level economic literature now establishes is achievable, against the firm’s current revenue stack. Do not let the assessment be performed by the incumbent CPQ vendor or by a partner with a single-vendor commercial stake. The assessment should answer four questions: where is revenue intelligence value being captured today; where is it being foregone; what is the architectural ceiling on the foregone value given the current CPQ engine; and what is the trajectory of that ceiling over the next 36 months given announced vendor roadmaps.
Second: stand up the intelligence layer in the next two quarters, regardless of whether the architectural decision has been made. The MCP-wrap of the legacy CPQ, the unified data layer, and the analytical revenue intelligence flows are no-regret moves that capture meaningful EBITDA on their own and generate the data needed to make the architectural decision with quantitative evidence rather than vendor assertions. This is also where the Kim, Kim, and Koning mapping problem gets solved at the firm level — by discovering empirically which AI use cases create value in your specific revenue function, rather than adopting a vendor’s generic playbook.
Third: decide the AI control plane question explicitly, not by accident. Whether the agentic revenue architecture sits on Salesforce Agentforce, SAP Joule, AWS AgentCore, Microsoft Foundry, Google’s Gemini Enterprise, or some federation across them is a strategic decision with multi-year consequences. It should be made by the executive team based on the firm’s existing platform commitments and integration topology, not by the vendor that closes the next deal.
Fourth and finally: sequence the migration to compound, not to optimize a single phase. The companies that get this right run the intelligence layer, the catalog rationalization, the engine migration, and the control plane build in parallel and overlapping phases, with each independently value-positive. The companies that get it wrong commit to a monolithic CPQ migration framed as a system replacement, hit the catalog rationalization cliff that has killed every previous generation of CPQ migration, and either fail the program or stretch it to twice its budget and timeline.
Readers thinking about how the revenue intelligence decision sits inside a broader enterprise AI portfolio — including cost displacement, contract analysis, manufacturing robotics, and the emerging physical AI category — may find the Enterprise AI Portfolio — Workflow Economics Framework useful as the wider capital allocation map at grikard.github.io/enterprise-ai-portfolio-framework. Revenue intelligence is one workflow domain within that broader portfolio; the architectural argument made in this paper applies specifically to the revenue intelligence quadrant and does not generalize cleanly to cost displacement workflows, which operate on a different equation.
Companies don’t buy systems. They buy outcomes. The outcome on offer in 2026 is measurable — peer-reviewed economic literature now establishes that AI-driven revenue intelligence produces capital efficiency and revenue velocity at the firm level, not just task-level productivity gains. The lift is meaningful enough to compound into structural EBITDA margin advantage by the end of the decade. But the lift compounds only when the architectural foundation underneath supports it, which means the gating dependency for the revenue intelligence outcome is the CPQ architecture. The CPQ decision is not the prize. It is the door.
The companies that walk through it in 2026 will compound two to three points of EBITDA margin between now and 2029, on top of whatever else they are doing. That is not a marginal improvement. It is a structural one, and it accrues to the operating leverage of the entire enterprise.
The revenue intelligence imperative is the quiet capital allocation decision of our era. It deserves to be made loudly, by the executives who will be accountable for the outcome, with the architectural depth that turns the decision from vendor selection into strategic transformation.
About the author
Gary Rikard leads Global Alliances and Business Development at HCLTech, with focus on enterprise platforms and edge services, cross-platform AI orchestration, and the workflow economics of enterprise AI adoption. The Workflow Economics series analyzes AI investment through capital allocation rather than technology-first lenses. This paper draws on engagements with enterprise customers across regulated industries, manufacturing, telecommunications, media, and high tech.
The views expressed are the author’s own and do not necessarily represent HCLTech.
References
Brynjolfsson, E., Li, D., & Raymond, L. (2025). Generative AI at Work. The Quarterly Journal of Economics, 140(2), 889–942. (NBER Working Paper No. 31161, April 2023.)
Codd, E. F. (1970). A relational model of data for large shared data banks. Communications of the ACM, 13(6), 377–387.
Dell’Acqua, F., McFowland, E., III, Mollick, E. R., Lifshitz-Assaf, H., Kellogg, K., Rajendran, S., Krayer, L., Candelon, F., & Lakhani, K. R. (2025, forthcoming). Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of Artificial Intelligence on Knowledge Worker Productivity and Quality. Organization Science. DOI: 10.1287/orsc.2025.21838. (Harvard Business School Working Paper No. 24-013, September 2023.)
Felfernig, A., Hotz, L., Bagley, C., & Tiihonen, J. (Eds.). (2014). Knowledge-Based Configuration: From Research to Business Cases. Morgan Kaufmann.
Junker, U. (2006). Configuration. In F. Rossi, P. van Beek, & T. Walsh (Eds.), Handbook of Constraint Programming (Chapter 24). Foundations of Artificial Intelligence, Vol. 2. Elsevier.
Kim, H., Kim, D., & Koning, R. (2026). Mapping AI into Production: A Field Experiment on Firm Performance. INSEAD Working Paper No. 2026/20/STR (March 2026). SSRN: https://ssrn.com/abstract=6513481.
Mackworth, A. K. (1977). Consistency in networks of relations. Artificial Intelligence, 8(1), 99–118.
McKinsey & Company. (2026, February). Global Tech Agenda 2026: The new CIO mandate — strategy, speed, and scaled intelligence. Authors: Reil-Jerenz, A., Romanelli, G., Jogani, R., Catlin, T., Halawa, A., & Himatsingka, P.
Mittal, S., & Frayman, F. (1989). Towards a generic model of configuration tasks. Proceedings of the 11th International Joint Conference on Artificial Intelligence (IJCAI’89), Vol. 2, 1395–1401.
Noy, S., & Zhang, W. (2023). Experimental evidence on the productivity effects of generative artificial intelligence. Science, 381(6654), 187–192.
Patil, S. G., Zhang, T., Wang, X., & Gonzalez, J. E. (2023). Gorilla: Large Language Model Connected with Massive APIs. arXiv:2305.15334.
Pope, R., Douglas, S., Chowdhery, A., Devlin, J., Bradbury, J., Heek, J., Xiao, K., Agrawal, S., & Dean, J. (2023). Efficiently scaling transformer inference. Proceedings of the Sixth Conference on Machine Learning and Systems (MLSys 2023).
Sabin, D., & Weigel, R. (1998). Product configuration frameworks — a survey. IEEE Intelligent Systems, 13(4), 42–49.
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., & Scialom, T. (2023). Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems 36 (NeurIPS 2023).
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E. H., Le, Q. V., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems 35 (NeurIPS 2022), 24824–24837.
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. 11th International Conference on Learning Representations (ICLR 2023).
Industry references and protocol specifications
Anthropic. (2024, November). Model Context Protocol specification. https://modelcontextprotocol.io/specification
Linux Foundation. (2025, June). Agent2Agent (A2A) Protocol Project announcement. Open Source Summit North America.
NVIDIA. (2025, March 18). GTC 2025 Keynote. Jensen Huang. SAP Center, San Jose, California.
Salesforce. (2026, April 15). Introducing Salesforce Headless 360. TrailblazerDX 2026, San Francisco. https://www.salesforce.com/news/stories/salesforce-headless-360-announcement/
SAP. (2018). Advanced Variant Configuration (AVC) for SAP S/4HANA. Released in S/4HANA 1809 (On-Premise) / 1808 (Cloud). Constraint solver based on Gecode.